Zhiting (May) Mei
IRoM Lab | maymei@princeton.edu

Hi! I’m a fourth-year PhD Student at IRoM Lab in Princeton.
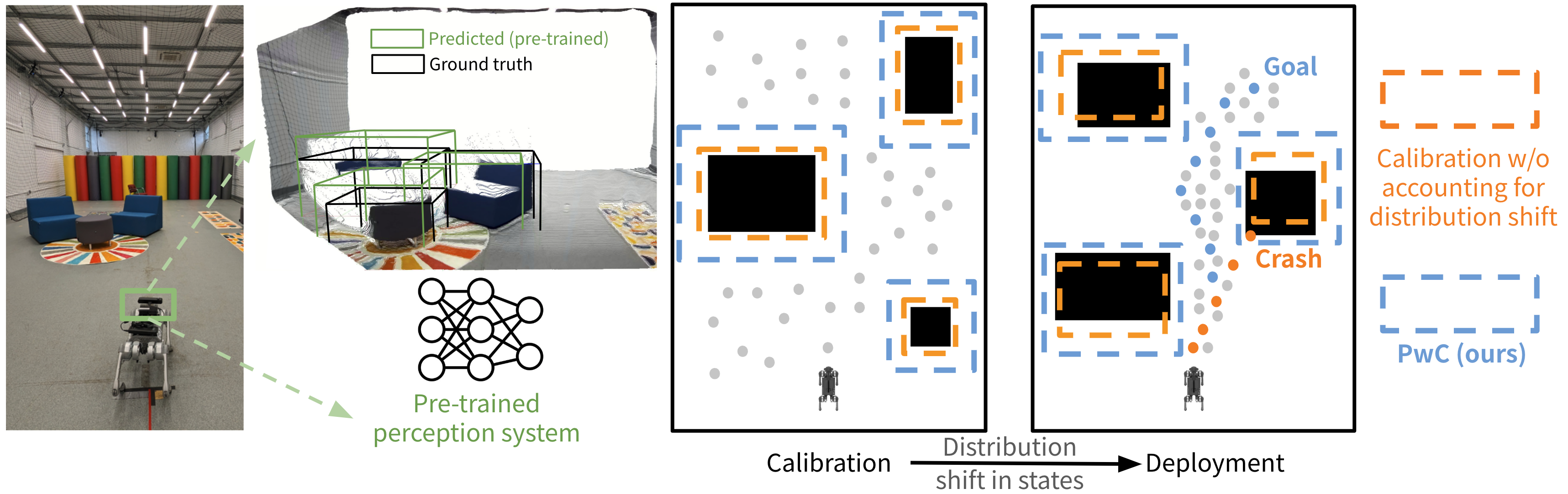
My research vision is to build capable, reliable, and trustworthy robots that can operate safely in the open world by understanding and managing uncertainty. To realize this vision, my work focuses on establishing both theoretical foundations and practical algorithms for uncertainty-aware embodied intelligence.
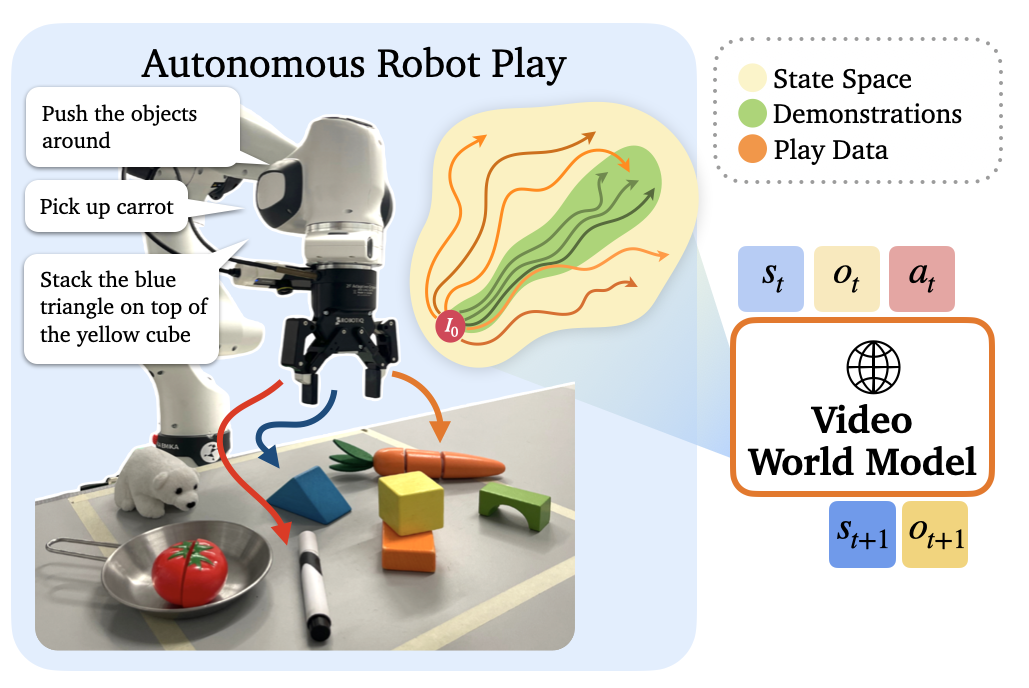
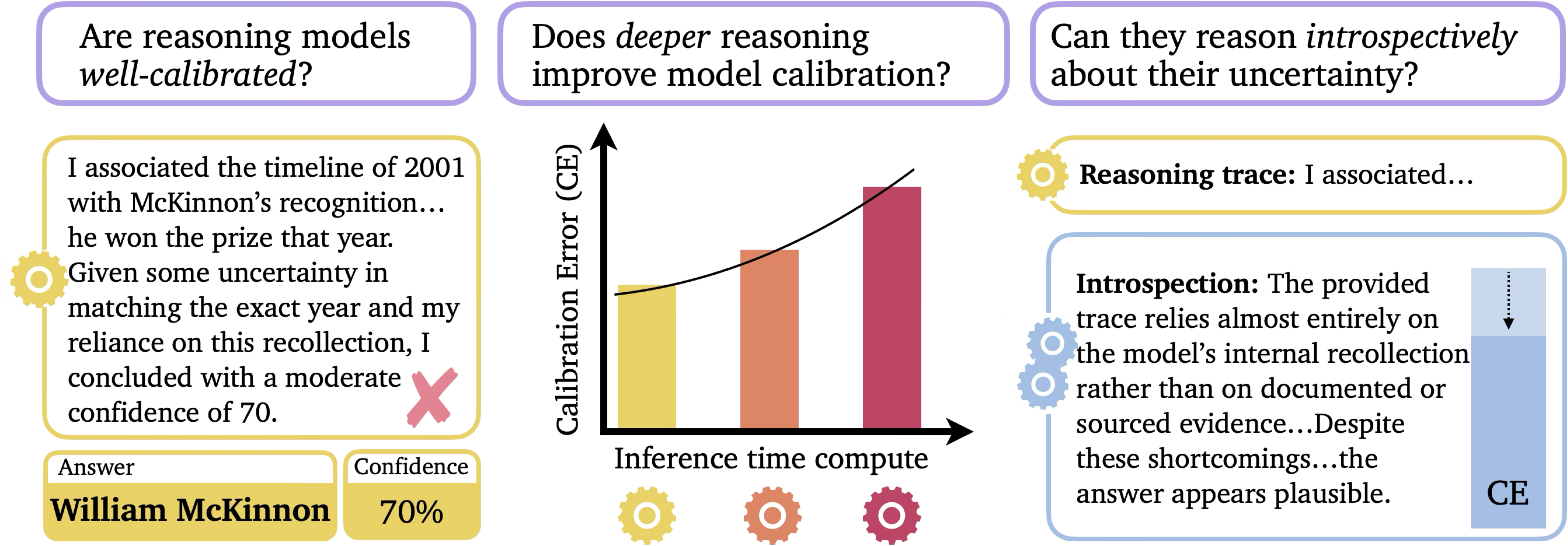
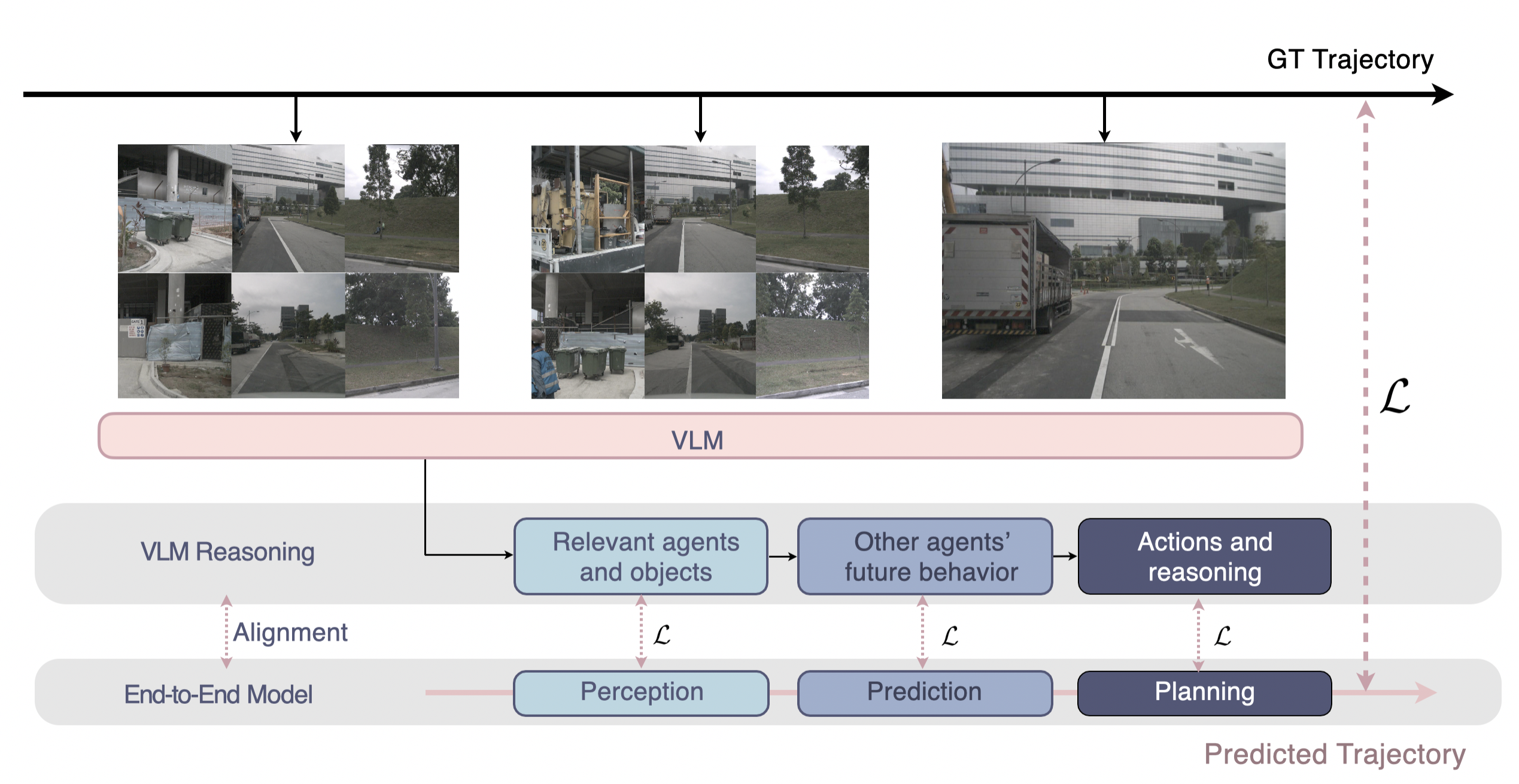
I aim to bridge the gap between specialist and generalist robots by understanding and improving generalization limits across perception, prediction, and reasoning. I work with generative video world models, large (reasoning) language models, vision foundation models, and vision-language-action models. Across these domains, I derive theoretical bounds on sensor-based and language-instructed autonomy, establish safety assurances via rigorous uncertainty quantification, probe generalizability of foundation models, and derive novel uncertainty quantification methods, improving both the performance and calibration of embodied AI.
news
| May 04, 2026 | I’m starting a research internship at Apple! |
|---|---|
| Mar 17, 2026 | I gave a talk at Google DeepMind reading group on PlayWorld with Tenny Yin and Ola Shorinwa! |
| Mar 12, 2026 | I gave a talk at Intent Lab on Trustworthy World Modeling! |
| Feb 24, 2026 | I gave a talk at Apple reading group on Trustworthy World Modeling! |
selected publications
-
 Video Generation Models in Robotics: Applications, Research Challenges, Future DirectionsarXiv preprint arXiv:2601.07823, 2026
Video Generation Models in Robotics: Applications, Research Challenges, Future DirectionsarXiv preprint arXiv:2601.07823, 2026